|
I am a Postdoctoral Scientist at Amazon Search Science & AI, working at the intersection of video understanding and large language models. I recently completed my Ph.D. journey at the Center for Research in Computer Vision, UCF, where I was advised by Prof. Mubarak Shah. I have a broad interest in various topics in computer vision and machine learning. My Ph.D. research primarily focused on learning with limited labels, including semi-supervised learning, few-shot learning, and self-supervised learning. I have also worked on activity detection, temporal action localization, learning with noisy labels, and multi-modal learning. |

|
|
February 2024: Paper accepted to CVPR 2024 |
|
|
|
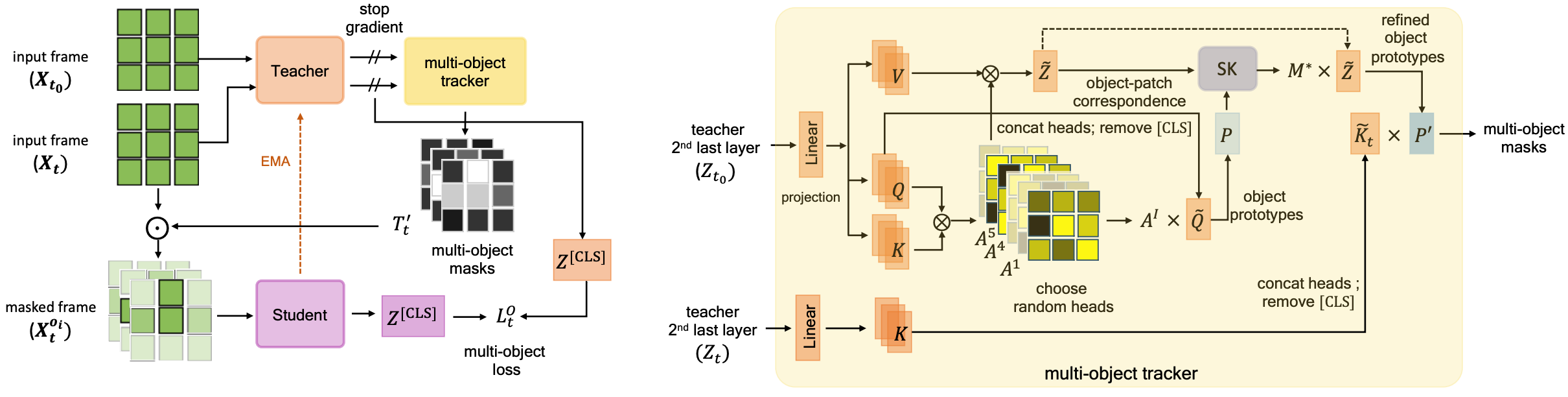
Shashanka Venkataramanan, Mamshad Nayeem Rizve, João Carreira, Yuki M. Asano*, Yannis Avrithis* ICLR, 2024 (Oral presentation; in top 1.2%) arxiv / openreview / project page / dataset / code / bibtex Using just “1 video” from our new egocentric dataset - Walking Tours, we develop a new method that outperforms DINO pretrained on ImageNet on image and video downstream tasks. |
|
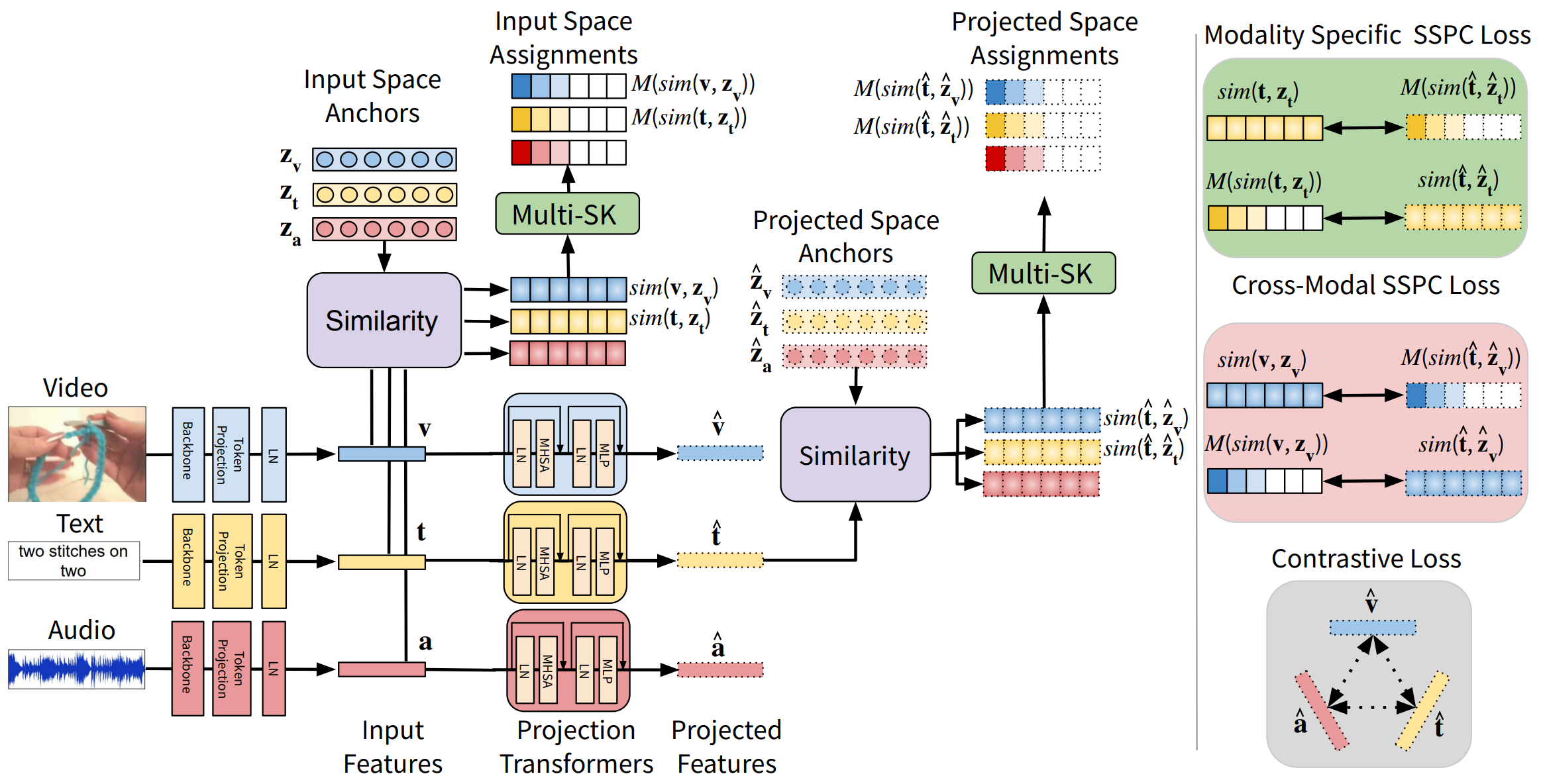
Sirnam Swetha, Mamshad Nayeem Rizve, Nina Shvetsova, Hilde Kuehne, Mubarak Shah ICCV, 2023 arxiv / bibtex Multi-modal self-supervised methods struggle with out-of-domain data due to ignoring the inherent modality-specific semantic structure. To address this issue, we introduce a Semantic-Structure-Preserving Consistency approach that preserves modality-specific relationships in the joint embedding space by utilizing a Multi-Assignment Sinkhorn-Knopp algorithm. This approach achieves state-of-the-art performance across various datasets and generalizes to both in-domain and out-of-domain datasets. |
|
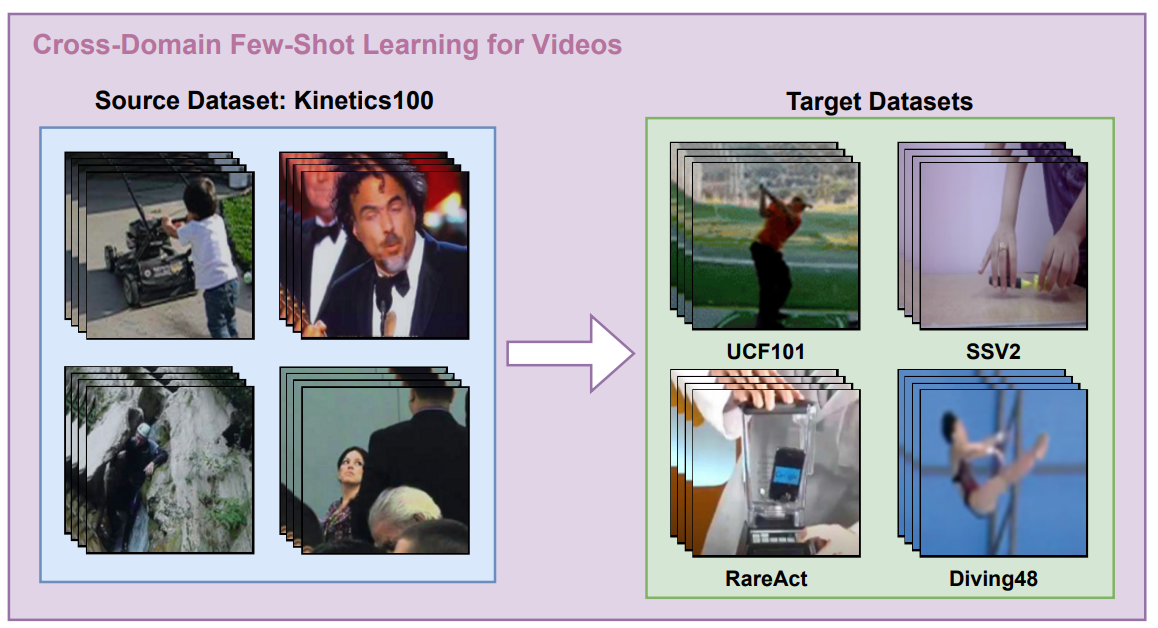
Sarinda Samarasinghe, Mamshad Nayeem Rizve, Navid Kardan, Mubarak Shah ICCV, 2023 arxiv / bibtex / code We introduce CDFSL-V, a challenging cross-domain few-shot learning problem in the video domain. We present a carefully designed solution that uses self-supervised learning and curriculum learning to balance information from the source and target domains. Our approach employs a masked autoencoder-based self-supervised training objective to learn from both domains and transition from class discriminative features in the source data to target-domain-specific features in a progressive curriculum. |
|
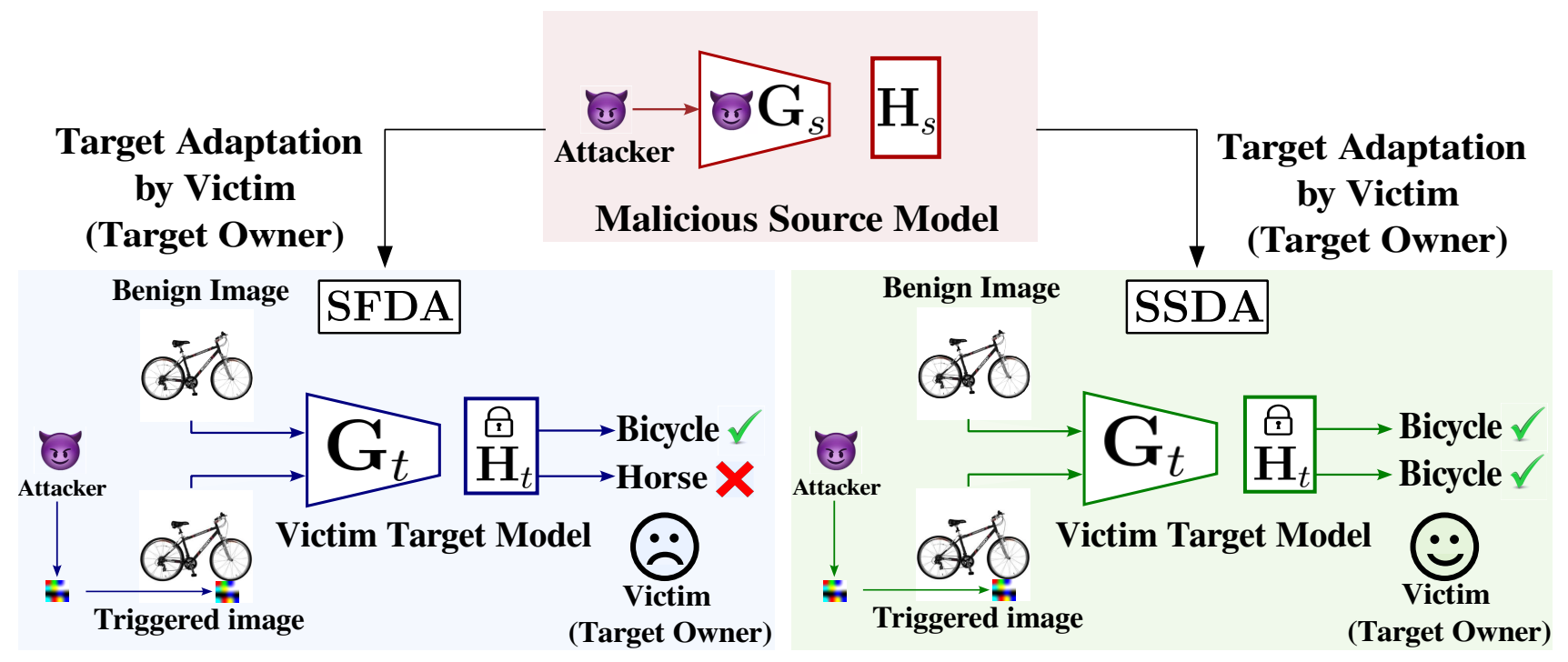
Sabbir Ahmed*, Abdullah Al Arafat*, Mamshad Nayeem Rizve*, Rahim Hossain, Zhishan Guo, Adnan Siraj Rakin ICCV, 2023 paper/ bibtex/ code We analyze the security challenges in Source-Free Domain Adaptation (SFDA), where the target domain owner lacks access to the source dataset and is unaware of the source model's training process, making it susceptible to Backdoor/Trojan attacks. We propose secure source-free domain adaptation (SSDA), which uses model compression and knowledge transfer with a spectral-norm-based penalty to defend the target model from backdoor attacks. Our evaluations demonstrate that SSDA effectively defends against such attacks with minimal impact on test accuracy. |
|
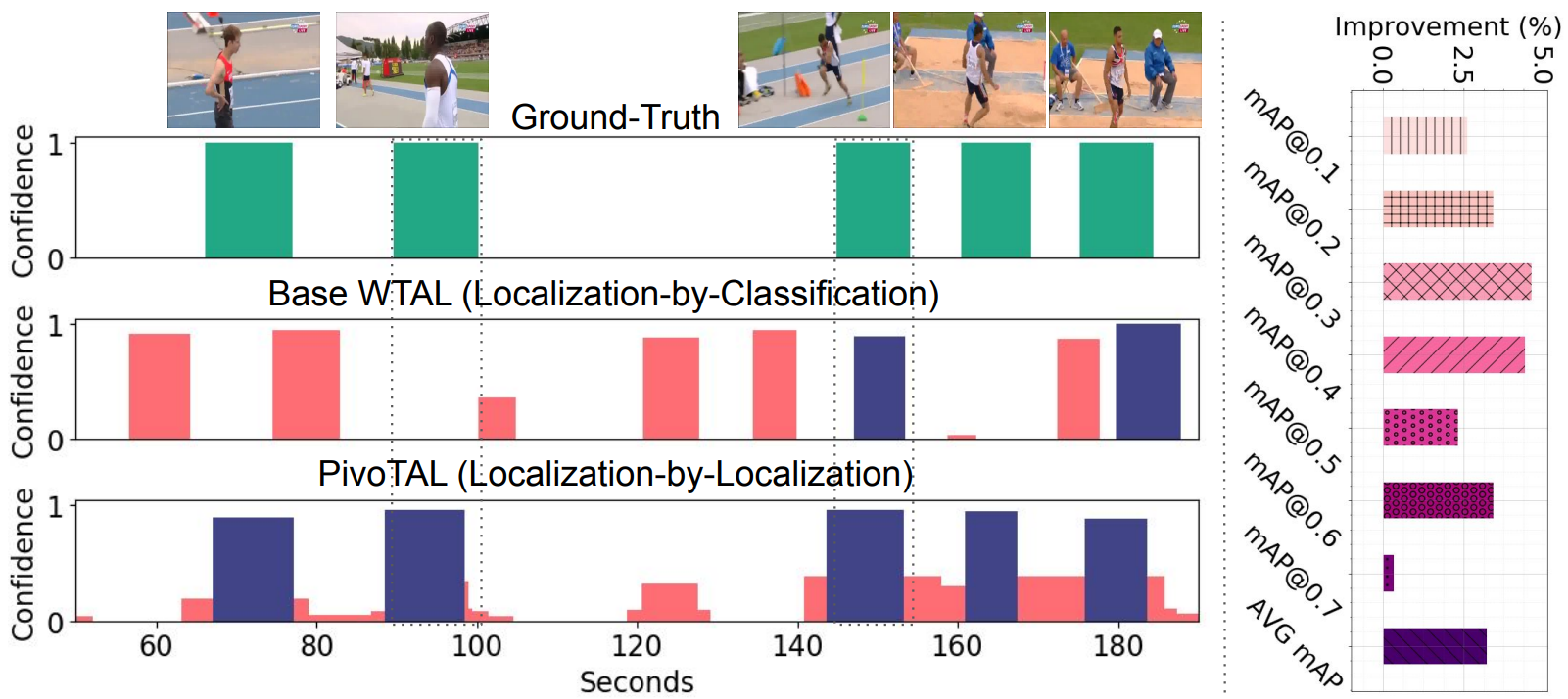
Mamshad Nayeem Rizve*, Gaurav Mittal*, Ye Yu, Matthew Hall, Sandra Sajeev, Mubarak Shah, Mei Chen CVPR, 2023 paper/ bibtex / video PivoTAL approaches Weakly-Supervised Temporal Action Localization from localization-by-localization perspective by learning to localize the action snippets directly. To this end, PivoTAL introduces a novel algorithm that exploits the inherent spatiotemporal structure of the video data in the form of action-specific scene prior, action snippet generation prior, and learnable Gaussian prior to generate pseudo-action snippets. These pseudo-action snippets provide additional supervision, complementing the weak video-level annotations during training. |
|
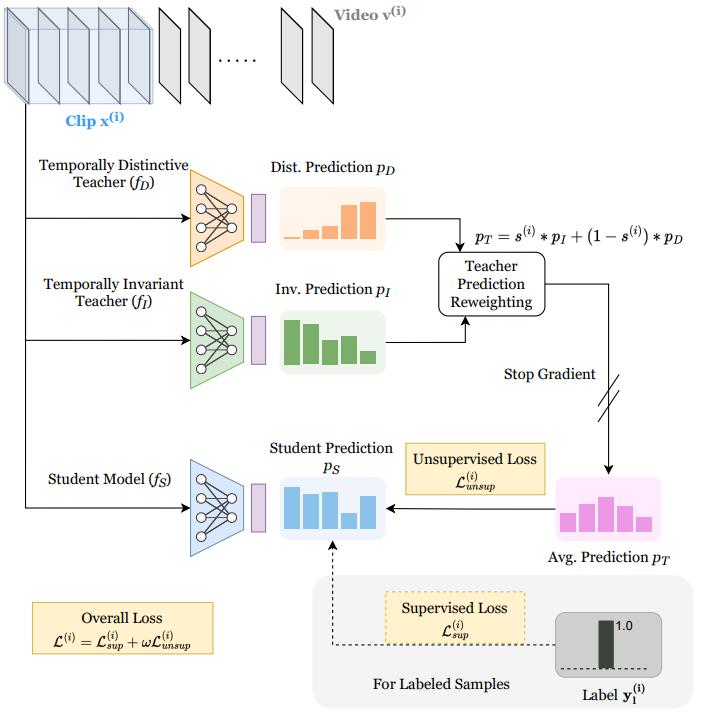
Ishan Dave, Mamshad Nayeem Rizve, Chen Chen, Mubarak Shah CVPR, 2023 arxiv/ bibtex / code We propose a student-teacher semi-supervised learning framework, where we distill knowledge from a temporally-invariant and temporally-distinctive teacher. Depending on the nature of the unlabeled video, we dynamically combine the knowledge of these two teachers based on a novel temporal similarity-based reweighting scheme. |

|
Mamshad Nayeem Rizve, Navid Kardan, Mubarak Shah ECCV, 2022 (Oral presentation; in top 2.7%) arxiv / bibtex / code We propose a new method for open-world semi-supervised learning that utilizes sample uncertainty and incorporates prior knowledge about class distribution to generate reliable class-distribution-aware pseudo-labels for samples belonging to both known and unknown classes. |
|
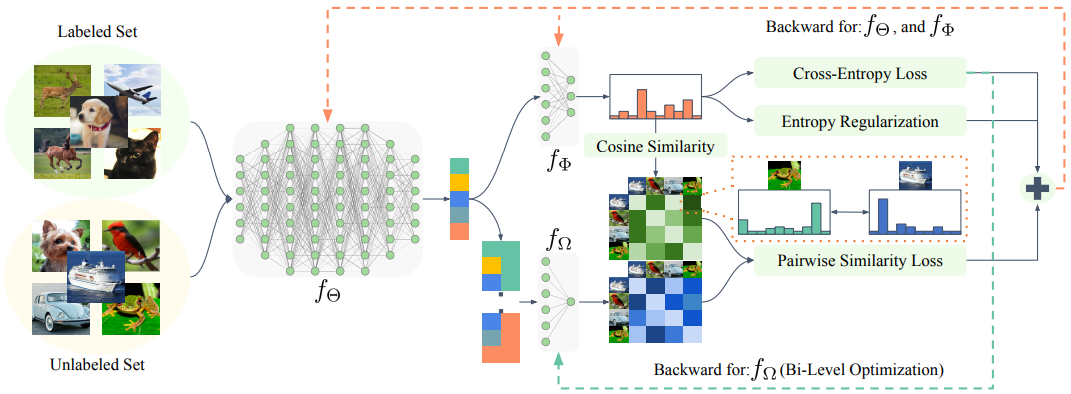
Mamshad Nayeem Rizve, Navid Kardan, Salman Khan, Fahad Shahbaz Khan, Mubarak Shah ECCV, 2022 arxiv / bibtex / code OpenLDN utilizes a pairwise similarity loss with bi-level optimization to discover novel classes and transforms the open-world SSL problem into a standard SSL problem, outperforming current state-of-the-art methods with better accuracy/training time trade-off. |
|
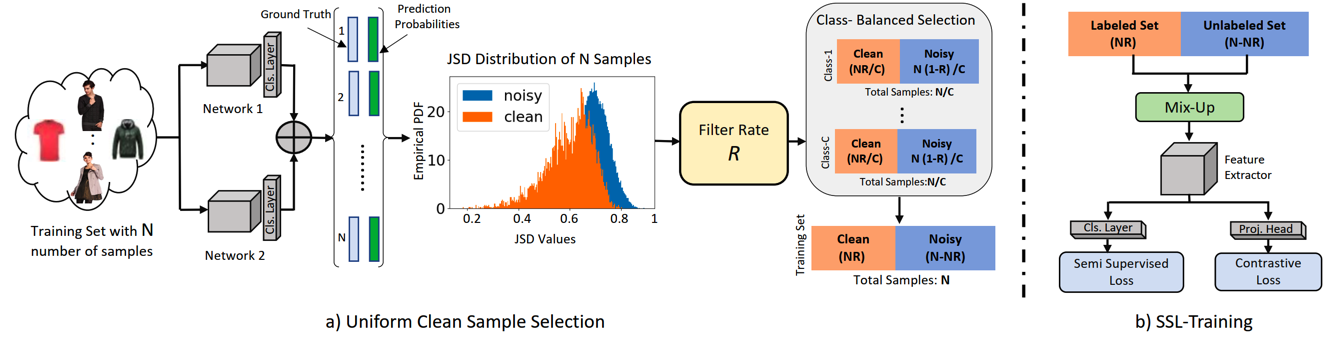
Nazmul Karim, Mamshad Nayeem Rizve, Nazanin Rahnavard, Ajmal Mian, Mubarak Shah CVPR, 2022 arxiv / bibtex / code UNICON is a robust sample selection approach for training with high label noise. It incorporates a Jensen-Shannon divergence based uniform sample selection mechanism and contrastive learning. |
|
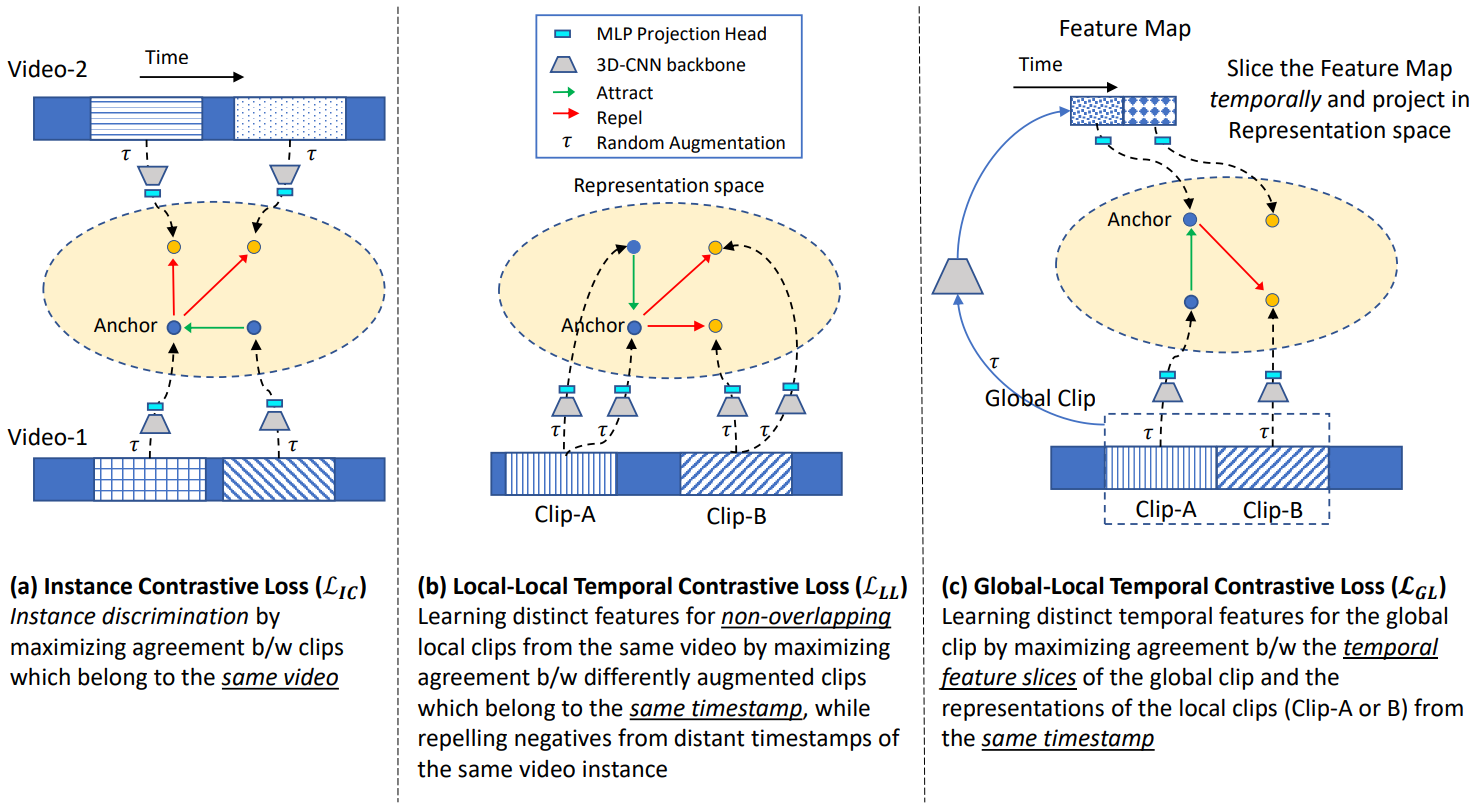
Ishan Dave, Rohit Gupta, Mamshad Nayeem Rizve, Mubarak Shah CVIU, 2022 arxiv / elsevier / bibtex / code / video We propose a new temporal contrastive learning framework for self-supervised video representation learning, consisting of two novel losses that aim to increase the temporal diversity of learned features. The framework achieves state-of-the-art results on various downstream video understanding tasks, including significant improvement in fine-grained action classification for visually similar classes. |
|
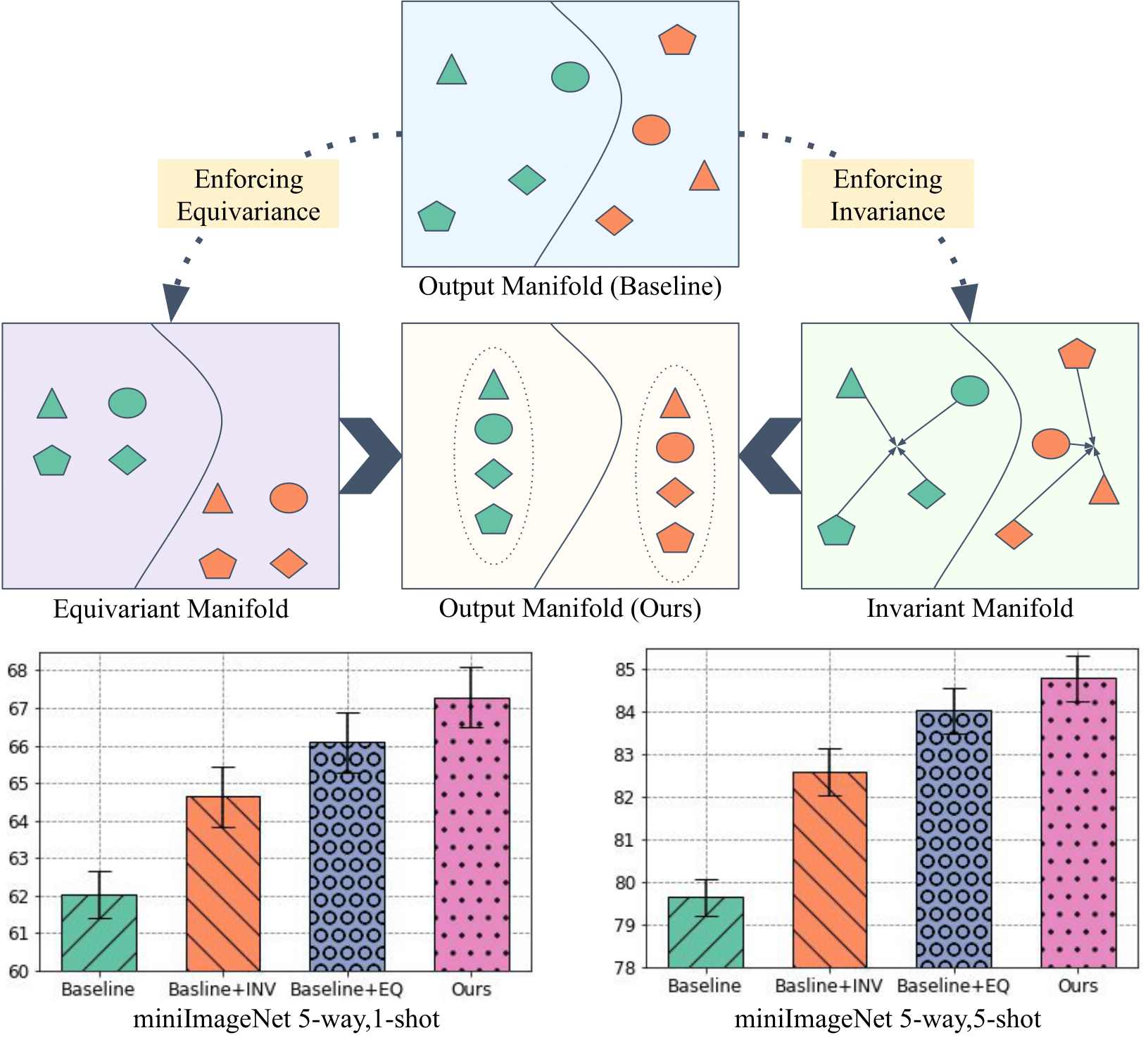
Mamshad Nayeem Rizve, Salman Khan, Fahad Shahbaz Khan, Mubarak Shah CVPR, 2021 arxiv / bibtex / code / video We propose a novel training mechanism for few-shot learning that simultaneously enforces equivariance and invariance to geometric transformations, allowing the model to learn features that generalize well to novel classes with few samples. |
|
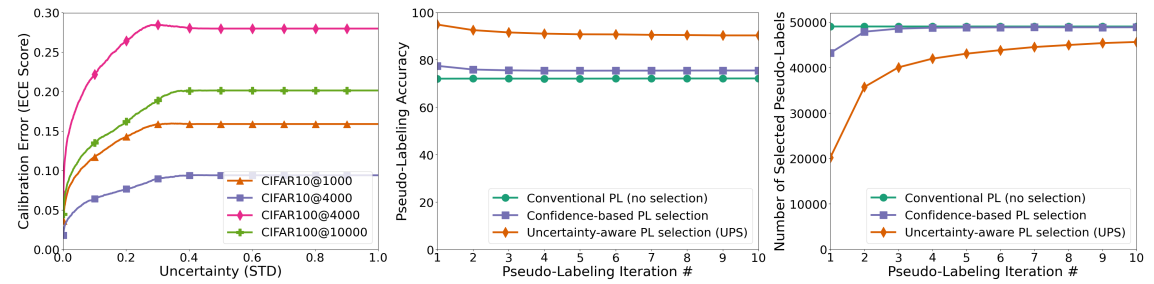
Mamshad Nayeem Rizve, Kevin Duarte, Yogesh S Rawat, Mubarak Shah ICLR, 2021 arxiv / openreview / bibtex / code / video We propose an uncertainty-aware pseudo-label selection (UPS) framework that reduces pseudo-label noise encountered during training, and allows for the creation of negative pseudo-labels for multi-label classification and negative learning. |
|
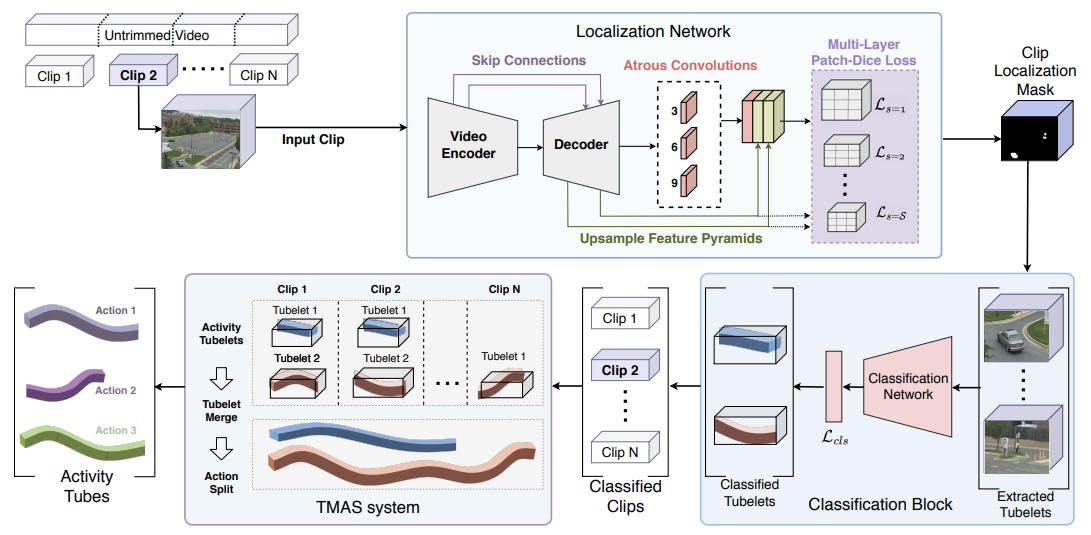
Mamshad Nayeem Rizve, Ugur Demir, Praveen Tirupattur, Aayush Jung Rana, Kevin Duarte, Ishan Dave, Yogesh S Rawat, Mubarak Shah ICPR, 2020 (Best paper award) arxiv / project page / bibtex / slides / video Gabbriella consists of three stages: tubelet extraction, activity classification, and online tubelet merging. Gabriella utilizes a localization network for tubelet extraction, with a novel Patch-Dice loss to handle variations in actor size, and a Tubelet-Merge Action-Split (TMAS) algorithm to detect activities efficiently and robustly. |
|
|

|
Yogesh S Rawat, Mubarak Shah, Aayush Jung Rana, Praveen Tirupattur, Mamshad Nayeem Rizve US Patent 11468676 Details |